The Problem with Data Strategy
Background
In my last 2 articles, I wrote about the need for the Data Analytics function to have a more overt stake and ownership of the campaign management and sales incentive management processes for any given organisation, seeing how these activities are extremely data-centric. In this 8th article, I want to expand that thinking into something more strategic — the larger construct of building Data Analytics capabilities for an organisation. This will take several articles to articulate.
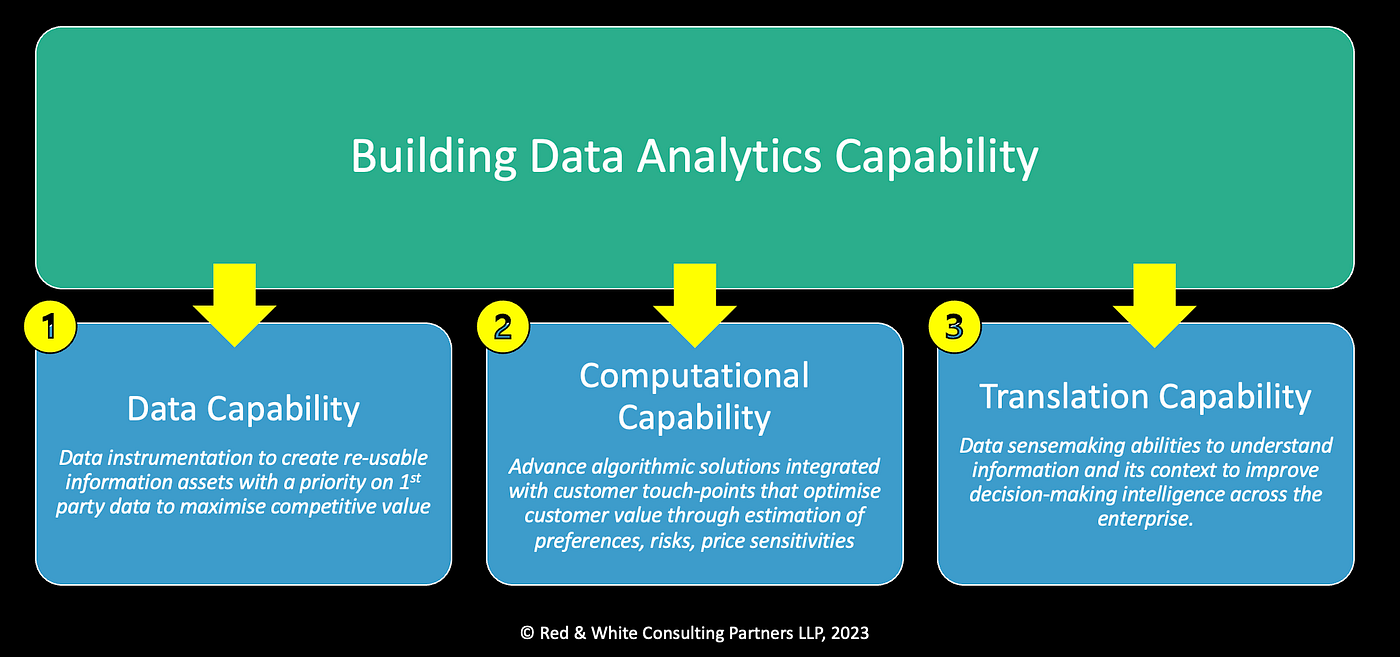
Let’s start at the top. What does it mean to build Data Analytics capabilities? I’ve spent my entire professional career unpacking this construct, and through my consulting, I’ve had the opportunity to further test and refine it with various clients across different industries. I’ve landed on a simple construct — there are really only 3 independent foundational (sub) capabilities to build out to achieve the overall enterprise-level data analytics capabilities. These are Data capability, Computational capability, and Translation capability. The diagram below provides a brief outline of what each means:
- Data capability — thoughtful data instrumentation strategy and methodology to create re-usable information assets with a priority on 1st party data to maximise competitive value.
- Computation capability — advance algorithmic solutions integrated with customer touch-points that optimise customer value through estimation of preferences, risks, price sensitivities.
- Translation capability — Data sensemaking abilities to understand information and its context to improve decision-making intelligence across the enterprise.
Let me unpack data capability in this article, as it’s one of the thorniest ones. Most people don’t realise that improving the accuracy of a predictive model has more to do with the quality of the data than the sophistication of the algorithms — data trumps algorithm every single time! Despite all the bluster about how important data is in creating competitive advantage, there are articles that estimate that less than 1% of data in an organisation is ever analysed. Citibank was a pioneer and leader in data warehousing and data analytics in Asia Pacific during my time with the bank, and even then, I had estimated that we were using only 15% of all the variables available to use in the data warehouse. Are organisations getting their data strategy wrong? Are they approaching data capability building in the wrong way?
Bad Thinking in Data Capability
There is a lot of mis-information and bad considerations when it comes to how organisations think about data. The idea that data is the new oil is an incorrect comparison. The belief that we should strive for one version of the truth with data warehousing is misplaced. Data is not like oil at all. Oil has near-limitless shelf-life but can only be used once. Data, on the other hand, has limited shelf-life but can be re-used multiple times. So they have entirely different economic value. The saying “use it or lose it” applies to data.
Data is not information. Data is not objective. Data is simply symbolic representation. Our interpretation of data turns it into information, and that makes information probabilistic and subjective. When we argue about the ‘meaning’ of a particular data, we are, in fact, arguing about its interpreted information; the same data can obviously give rise to different information. So there is no single version of the truth, no matter how you centralise or control the access to the data. And we shouldn’t be wasting our time to force-converge on one interpretation of the data, but rather, to respect and understand the need for multiple interpretations that are context useful. Consider the simple question: how many customers do we have in this bank? For Finance, the answer would be based on everyone, dead or alive, that has either an outstanding asset or liability with the bank. For Marketing, it would be everyone alive who still has a relationship with the bank. For Risk, it would exclude the customers written-off. Each of these functions are perfectly right in the way they count the number of customers as it relates directly to their realm of responsibilities and what they have control over.
Organisations also spend an inordinate amount of time ‘crippling’ their data services — creating nonsensical restrictive data access policies such as “… on a need to know basis …”. These policies pre-supposes that employees know what data they need, which is nearly always not the case. Data is meant to be used and re-used as widely as possible, but it is the knowledge outcome derived from its use that should be protected, and in some cases, restricted.
Data Strategy
Building data capability requires a keen understanding of what the data will be used for; it requires strategic intent. You have to ask yourself a whole bunch of questions:
- What data would I need?
- Why would I such data; how do I intend to use it?
- How would I efficiently collect such data?
- Is this data unique to my operatiung context or is it easily replicable by my competitors?
- etc.
Most organisations start their data capability in reverse. They look at what data they already have, and figure out how to centralise it, how to clean it. And then they discuss how they might use it. That’s just plain wrong.
A helpful way to start is to consider the 3 large ways in which data can create competitive capabilities: Data-for-Automation, Data-for-Decision and Data-for-Product.
Data-for-Automation
Data-for-Automation (DfA) is about leveraging data to reduce process friction and increase the speed of decisioning.
Does your organisation spend a lot of time foraging and compiling data & information to put it in front of an employee so that they can start their decisioning process? E.g. a banking product manager might need to constantly review competitor pricing and customer responses and feedback to adjust their product pricing in an ultra price-sensitive area. It would then make perfect sense to automate the data collection process (in some cases, you may need to rely on data proxies) so that the product manager can make faster decisions, giving the organisation an agile advantage that can be monetised.
DfA does not threaten the livelihood of employees. Rather, it empowers the employee. DfA is generally welcomed, and is the easiest of the data strategy to initiate. DfA correlates with investments in API, data platforms, data quality and data access.
Data-for-Decision
Data-for-Decisions (DfD) is about leveraging data to reduce uncertainty in decision-making, thereby improving the quality of its outcome.
Does your organisation make many decisions without the ‘full deck of cards’ and have to ‘guess’ the most likely outcome based on past experiences or business intuition? E.g. a banking product manager might decide to follow suit and offer a similar product just because a competitor is doing so. Is there a genuine market demand and how large is it to warrant a response? Is there an expectation from your existing customers that your bank should be fulfilling this market demand? It would then make sense to instrument data that might be helpful to test and validate these hypotheses, to reduce the guesswork through a closed-loop data-driven feedback mechanism.
DfD can threaten the livelihood of employees as it challenges the quality of their current decision-making. It is harder to implement because of this natural resistance. But this is where data can create the greatest impact. DfD includes the creation of the right performance and feedback metrics so that the quality of decision outcomes can be properly assessed and continuously fine-tuned. It would also include shortlisting and prioritisation of decision choices. DfD correlates with data definition, data visualisation and data governance.
Data-for-Product
Data-for-Product (DfP) is about leveraging data to improve the features and functionalities of your product offering, thereby creating more demand for your products.
Can your organisation significantly improve its products and services by enriching or automating it with more data & information? E.g. a banking product manager might introduce a customer-facing recommendation engine that connects real-time financial investment news with straight-through portfolio buy/sell capabilities, enabling the end-customer to trade with increased assurance of returns while reducing their ‘fear of missing out’ (FOMO).
DfP requires serious thoughtfulness on data collection and end-to-end data execution capabilities. It requires the ability to instrument for journeys and experiences. DfP correlates with data instrumentation, data protection, data privacy, and it intersects with the pursuit of Computational capability.
Conclusion
Building data capability isn’t about building a data warehouse or data lake or whatever they might call it these days. It isn’t about data governance or data privacy. It is about understanding the nature of the corporate vehicle you are driving, and the kind of fuel that you need to power it up and create significant competitive advantage.
